[deprecated] kaggleのタイタニックとたわむれる
【2021-06-15 更新】本記事の内容は時代遅れです。 ちょっと立て込んでいて修正できてませんが、 『Kappleで勝つデータ分析の技術』を難しいと感じる層向けに アップデートしようと考えています(非常に良い本です)。 まぁ、初学者の頃はこうしていた、というログできな意味で 残しておくのは価値があるかもしれないので、 その際は新規リンクを貼ります。
【2019-12-14 追記】もう少し内容を整理して書き直しますのでしばしお待ちを…
kaggleデビューしました
1月30日に初心者向けのkaggleチュートリアル があったので参加してきました。 サポーターズさんの勉強会にはしばしばでているのですが、 今回のチュートリアルは完成度が高くていろいろと参考になりました。
特に勉強になったのは以下の点です。
- データを分割して訓練データとテストデータにすると提出前にスコアが推測できる。 (授業で確かに聞いた覚えはあったのですが、実践できていませんでした。)
- 安直な前処理よくない。というのも、 前処理だけの本があるくらい奥深い世界みたいです。なんでも平均値で埋める、というのはよろしくないようです。
- 面白いのは分析(このデータは使えそう、みたいなやつ)
- kernelがチュートリアルには便利
というか資料の完成度も高いので今後自分がチュートリアルする時の参考にもしたいです。
タイタニック号の分析
べたべたにチュートリアルを賞賛して終わるのもなんなので、 いちおう目標の0.765も超えたので「解き方の例」みたいなのを残しておきます。
まずはデータを読み込みます。 それぞれの列のデータの説明は以下の通りです。 Training dataとTest dataがあって、 Testデータのほうには”Survived”がありません。
- PassengerId
- Survived: Survived (1) or died (0)
- Pclass: Passenger’s class
- Name: Passenger’s name
- Sex: Passenger’s sex
- Age: Passenger’s age
- SibSp: Number of siblings/spouses aboard
- Parch: Number of parents/children aboard
- Ticket: Ticket number
- Fare: Fare
- Cabin: Cabin
- Embarked: Port of embarkation
予測したい変数は “Survived” なので、 まずはデータを整理、可視化して役立ちそうな変数を見つけ、 次にTraining dataでモデルを立てて、 最後にTest dataのPassengerIdごとにSurvivedを求める、 という流れになります。
データの取得と整理、統計量の確認
まずはトレーニングデータとテストデータを読み込ます。 同時に欠損値があるかどうかも今のうちに見ておきます。 テストデータに欠損値があると 予測の時にNAになって成績を大きく下げるので対処せねばなりません。
#setwd("C:/Users/kishiyama/Document/formula-exercise")
train <- read_csv("../data/train.csv")
test <- read_csv("../data/test.csv")
sapply(train, anyNA)
## PassengerId Survived Pclass Name Sex Age
## FALSE FALSE FALSE FALSE FALSE TRUE
## SibSp Parch Ticket Fare Cabin Embarked
## FALSE FALSE FALSE FALSE TRUE TRUE
sapply(test, anyNA)
## PassengerId Pclass Name Sex Age SibSp
## FALSE FALSE FALSE FALSE TRUE FALSE
## Parch Ticket Fare Cabin Embarked
## FALSE FALSE TRUE TRUE FALSE
AgeとFare、その他の変数に欠損値がありそうです。 年齢と運賃はおそらく使うので平均と置き換えて対処します。 チュートリアルを受けるまえのコードなのですが、 いまだったら中央値とかをつかうかもしれません。 前処理も勉強が必要ですね。
train$Fare =ifelse(is.na(train$Fare),mean(na.omit(train$Fare)), train$Fare)
test$Fare = ifelse(is.na(test$Fare), mean(na.omit(test$Fare)), test$Fare)
train$Age = ifelse(is.na(train$Age), mean(na.omit(train$Age)), train$Age)
test$Age = ifelse(is.na(test$Age), mean(na.omit(test$Age)), test$Age)
この操作ですでに元のデータとは 違うものになっていますがまぁ妥協してよしとします。 この状態での統計量は以下の通りです。
train %>% summary
## PassengerId Survived Pclass Name
## Min. : 1.0 Min. :0.0000 Min. :1.000 Length:891
## 1st Qu.:223.5 1st Qu.:0.0000 1st Qu.:2.000 Class :character
## Median :446.0 Median :0.0000 Median :3.000 Mode :character
## Mean :446.0 Mean :0.3838 Mean :2.309
## 3rd Qu.:668.5 3rd Qu.:1.0000 3rd Qu.:3.000
## Max. :891.0 Max. :1.0000 Max. :3.000
## Sex Age SibSp Parch
## Length:891 Min. : 0.42 Min. :0.000 Min. :0.0000
## Class :character 1st Qu.:22.00 1st Qu.:0.000 1st Qu.:0.0000
## Mode :character Median :29.70 Median :0.000 Median :0.0000
## Mean :29.70 Mean :0.523 Mean :0.3816
## 3rd Qu.:35.00 3rd Qu.:1.000 3rd Qu.:0.0000
## Max. :80.00 Max. :8.000 Max. :6.0000
## Ticket Fare Cabin Embarked
## Length:891 Min. : 0.00 Length:891 Length:891
## Class :character 1st Qu.: 7.91 Class :character Class :character
## Mode :character Median : 14.45 Mode :character Mode :character
## Mean : 32.20
## 3rd Qu.: 31.00
## Max. :512.33
生存率はSurvivedの平均から38%くらいだとわかります。 年齢は月までの情報はいらないので四捨五入します。 名前も今回は使わないので落として、 生死の情報は実数でないので、ファクターとします。
train %>%
mutate(Age = round(Age),
Survived = as.factor(Survived),
Sex = as.factor(Sex),
PassengerId = NULL,
Ticket = NULL,
Name = NULL) %>%
na.omit ->
train.mutated
summary(train.mutated)
## Survived Pclass Sex Age SibSp
## 0: 68 Min. :1.000 female: 95 Min. : 1.00 Min. :0.0000
## 1:134 1st Qu.:1.000 male :107 1st Qu.:25.00 1st Qu.:0.0000
## Median :1.000 Median :33.50 Median :0.0000
## Mean :1.198 Mean :35.14 Mean :0.4455
## 3rd Qu.:1.000 3rd Qu.:46.75 3rd Qu.:1.0000
## Max. :3.000 Max. :80.00 Max. :3.0000
## Parch Fare Cabin Embarked
## Min. :0.0000 Min. : 0.00 Length:202 Length:202
## 1st Qu.:0.0000 1st Qu.: 28.96 Class :character Class :character
## Median :0.0000 Median : 55.00 Mode :character Mode :character
## Mean :0.4406 Mean : 76.10
## 3rd Qu.:1.0000 3rd Qu.: 89.78
## Max. :4.0000 Max. :512.33
データの整理はこれくらいにして、 何が生死を分けたのかを観察するためにデータを可視化します。
データの可視化
今回は変数が多いのでまずは GGallyパッケージで一度にそれぞれの変数間の関わり合いを見てみます。
library(GGally)
train.mutated %>%
ggpairs(mapping=aes(colour=Survived, alpha=0.5),
columns=c("Survived", "Pclass", "Sex", "Fare", "Embarked", "Age"),
upper=list(continuous="cor", combo="box", discrete="facetbar"),
diag=list(continuous="densityDiag", discrete="barDiag"),
lower=list(continuous="points", combo="facethist", discrete="facetbar"))
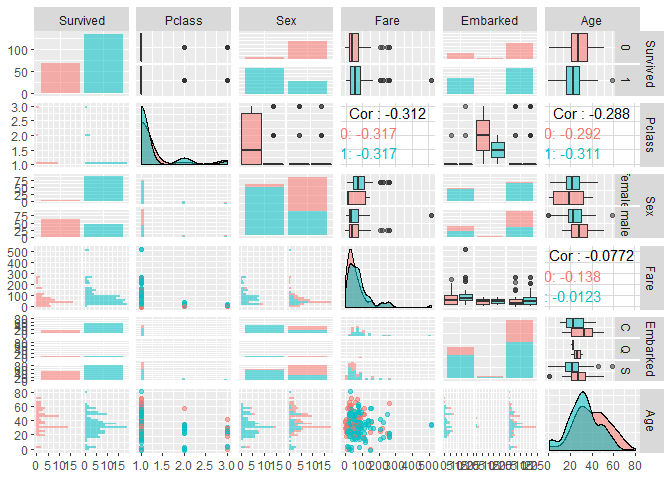
全体の傾向をつかむ分には割と使えそうです。 一番上の行の右を見ると”Survived”と書いてあります。 一行目の上の行は死亡(0,赤)、下の行は生存データ(1,青)が Pclass, Sex, Fare, Embarked, Ageの値でどう変わるか、を示しています。
そんなにがっつりとは分析しませんが、 気づいたことをまとめると以下の通り。
- 亡くなったのはだいたい男性。Sex列は右が男性、左が女性。
- どんな男性の生存率が下がるのか、が見どころかもしれません。 家族がいる男性でしょうか、お金のある、あるいは年齢の高い男性でしょうか。
- Pclass, Fareはわからない。
- 交互作用をにらむ
- Ageも死亡率が高い。
まぁ上のデータを見る限り女性だと大体助かりそうなので、 データを男性に絞って分析を続けます。
どんな男性がなくなったのかの分析
ここではtrain.mutated[with(train.mutated, Sex %in% c("male")), ]として データを男性に絞ります。別にfilter でもsubsetでもいいのですが。 すると以下のようなグラフになります。
library(GGally)
ggpairs(train.mutated[with(train.mutated, Sex %in% c("male")), ], mapping=aes(colour=Survived, alpha=0.5), columns=c("Survived", "Pclass", "Age", "SibSp", "Parch", "Fare", "Embarked"), upper=list(continuous="cor", combo="box", discrete="facetbar"), diag=list(continuous="densityDiag", discrete="barDiag"), lower=list(continuous="points", combo="facethist", discrete="facetbar"))
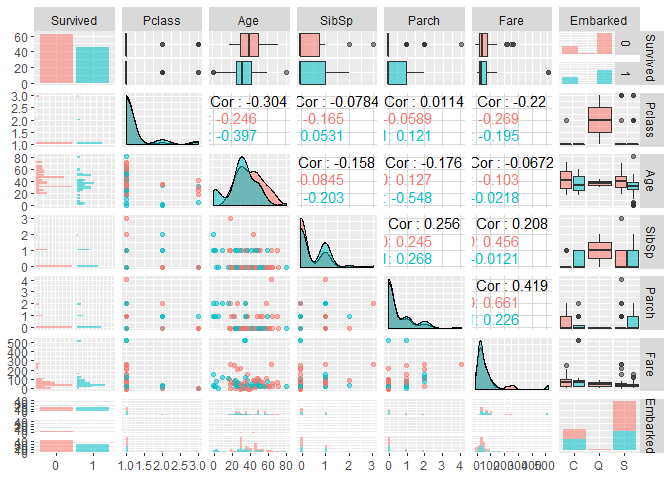
ちょっと興味深い点としてはSurvived列のAge行、 死亡は赤なのですが20未満で亡くなった男性は少ないように見えます。 また、Fareの行を見ると500あたりの人は生存しているように見えます。 ここから20歳未満か否か、という点と高額な運賃を払ったか、 という情報が性別と交互作用を持つと仮定しました。 (つまり、男性は死ぬ割合のほうが高いけど、若い/高い運賃は 生存率を上げる効果を持つ、という仮定です。) そこで新しい変数を作ってあげました。
train.mutated %>%
mutate(is.child=Age<20,
is.rich=Fare>400,
Age=NULL,
Fare=NULL,
SibSp=NULL,
Parch=NULL) ->
train.data
つかいそうなパラメターに絞って再度プロットします。
library(GGally)
ggpairs(train.data, mapping=aes(colour=Survived, alpha=0.5), columns=c("Survived", "Sex", "is.child", "is.rich"), upper=list(continuous="cor", combo="box", discrete="facetbar"), diag=list(continuous="densityDiag", discrete="barDiag"), lower=list(continuous="points", combo="facethist", discrete="facetbar"))
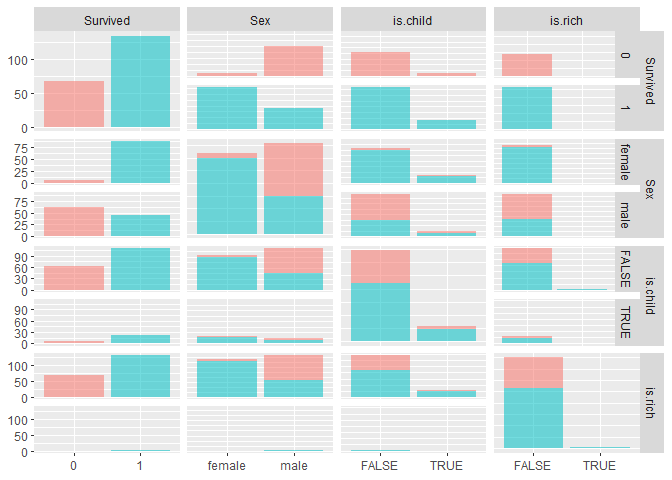
モデル作成
従属変数は0,1なので今回はロジスティック回帰します。 性別と年齢をモデルに入れて、あとは 性別と年齢、性別と運賃の交互作用を見ています。
set.seed(123)
model <- glm(Survived ~ Sex + is.child + is.child:Sex + is.rich:Sex,
family=binomial,
data =train.data)
summary(model)
##
## Call:
## glm(formula = Survived ~ Sex + is.child + is.child:Sex + is.rich:Sex,
## family = binomial, data = train.data)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.4374 -0.9718 0.3245 0.5003 1.3980
##
## Coefficients: (1 not defined because of singularities)
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 2.9178 0.5133 5.684 1.32e-08 ***
## Sexmale -3.4229 0.5562 -6.154 7.54e-10 ***
## is.childTRUE -0.9029 0.9111 -0.991 0.3217
## Sexmale:is.childTRUE 2.1011 1.1185 1.879 0.0603 .
## Sexfemale:is.richTRUE NA NA NA NA
## Sexmale:is.richTRUE 16.0712 1029.1215 0.016 0.9875
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 258.07 on 201 degrees of freedom
## Residual deviance: 182.32 on 197 degrees of freedom
## AIC: 192.32
##
## Number of Fisher Scoring iterations: 14
男性であると生存率は有意に落ちて、 子供であれば男性でも助かる可能性が上がる傾向があるようです。
モデルを用いた予測
テストデータにも同じ処理をしてあげます。
# survived
test %>%
mutate(Age = round(Age),
Sex = as.factor(Sex),
Ticket = NULL,
Name = NULL) %>%
mutate(is.child=Age<20,
is.rich=Fare>400,
Age=NULL,
Fare=NULL,
SibSp=NULL,
Parch=NULL) ->
test.mutate
そしてpredict関数にmodelとデータを与えます。 modelで指定した列を使ってデータを生成してくれます。 その結果をSurvivedという列に入れてデータフレームを作り、 閾値を0.5として0,1に変換します。 保存したcsvをkaggleに渡すと成績が出てきます。
prediction <- predict(model, test.mutate)
solution <-
data.frame(PassengerID = test$PassengerId, Survived = prediction) %>%
mutate(Survived=ifelse(Survived>0.5,1,0))
write.csv(solution, file = '../data/lr_solution.csv', row.names = F)
ドキドキ、という感じだったのですが精度は0.73で順位は9262位とまぁ、 僕の初kaggleは無事に爆死しました。
タイタニック号の分析2
とこのままでは悲しいので再チャレンジしました。
子供かどうか、運賃の情報などをわざわざ二値にしましたが、 あれは愚策化もしれません。というのもわざわざ使える情報を減らしているので…。 というわけで、今回は情報を削らずに試してみます。 さらに今回はほかの情報(Pclass, SibSp, Parch)も加えてモデルを作りました。
set.seed(123)
model.2 <- glm(Survived ~ Sex + Age + Fare + Pclass + SibSp + Parch +
Sex:Age + Sex:Fare,
family=binomial,
data =train)
summary(model.2)
##
## Call:
## glm(formula = Survived ~ Sex + Age + Fare + Pclass + SibSp +
## Parch + Sex:Age + Sex:Fare, family = binomial, data = train)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.6485 -0.6128 -0.4178 0.6054 2.5105
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 4.155064 0.580493 7.158 8.20e-13 ***
## Sexmale -1.324626 0.458656 -2.888 0.00388 **
## Age -0.012600 0.011955 -1.054 0.29188
## Fare 0.007053 0.006108 1.155 0.24818
## Pclass -1.096441 0.143573 -7.637 2.23e-14 ***
## SibSp -0.334915 0.106961 -3.131 0.00174 **
## Parch -0.145330 0.117990 -1.232 0.21805
## Sexmale:Age -0.046595 0.015231 -3.059 0.00222 **
## Sexmale:Fare -0.005184 0.006130 -0.846 0.39773
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 1186.7 on 890 degrees of freedom
## Residual deviance: 776.8 on 882 degrees of freedom
## AIC: 794.8
##
## Number of Fisher Scoring iterations: 6
そして 再度テストデータに当てはめて予測させます。
test %>%
mutate(Age = round(Age),
Sex = as.factor(Sex),
Ticket = NULL,
Name = NULL) ->
test.mutate
prediction.2 <- predict(model.2, test.mutate)
solution.2 <-
data.frame(PassengerID = test$PassengerId, Survived = prediction.2) %>%
mutate(Survived=ifelse(Survived>0.5,1,0))
write.csv(solution.2, file = '../data/lr_solution.2.2.csv', row.names = F)
精度0.77で6303位に。若干改善されました。 目標は超えたのですが、もうちょっと頑張ります。
タイタニック号の分析3
もうほかの性別とほかの要因の交互作用も見てしまいます。
# survived
test %>%
mutate(Age = round(Age),
Sex = as.factor(Sex),
Ticket = NULL,
Name = NULL) ->
test.mutate
model.3 <- glm(Survived ~ Sex + Age + Fare + Pclass + SibSp + Parch +
Sex:Age + Sex:Fare + Sex:Pclass + Sex:Parch,
family=binomial,
data =train)
summary(model.3)
##
## Call:
## glm(formula = Survived ~ Sex + Age + Fare + Pclass + SibSp +
## Parch + Sex:Age + Sex:Fare + Sex:Pclass + Sex:Parch, family = binomial,
## data = train)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.9068 -0.6186 -0.4613 0.4167 2.3752
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 7.849772 1.257028 6.245 4.25e-10 ***
## Sexmale -6.117563 1.376846 -4.443 8.86e-06 ***
## Age -0.025610 0.013754 -1.862 0.062597 .
## Fare -0.004721 0.005342 -0.884 0.376852
## Pclass -2.223577 0.378214 -5.879 4.12e-09 ***
## SibSp -0.339271 0.111152 -3.052 0.002271 **
## Parch -0.246737 0.151342 -1.630 0.103031
## Sexmale:Age -0.020016 0.016875 -1.186 0.235571
## Sexmale:Fare 0.006730 0.005880 1.145 0.252350
## Sexmale:Pclass 1.405349 0.409912 3.428 0.000607 ***
## Sexmale:Parch 0.566262 0.238164 2.378 0.017425 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 1186.66 on 890 degrees of freedom
## Residual deviance: 756.12 on 880 degrees of freedom
## AIC: 778.12
##
## Number of Fisher Scoring iterations: 6
prediction.3 <- predict(model.3, test.mutate)
solution.3 <-
data.frame(PassengerID = test$PassengerId, Survived = prediction.3) %>%
mutate(Survived=ifelse(Survived>0.5,1,0))
write.csv(solution.3, file = '../data/lr_solution.3.csv', row.names = F)
モデル3は精度0.78で5694位でした。うーん、という感じです。
以下、学んだことです。
- なんでも回帰、はちょっとよろしくないのかも。
- ランダムフォレストとか、分類に強い手法も知っておくとよいかも。
- データをつぶすと解釈は楽になるけど予測は悪くなる(当たり前)
- グラフと分析が同じである必要はないのでよしなに。
- Kaggleを取り掛かるまでにやったこととと、モチベーションの維持のために必要だったことというエントリーでの「挑み方」が大切だと感じた。このフローチャートを胸に刻みたい。
- 高い精度でかつ理解しやすいカーネルを覗きに行く。
- いい勉強になるけど自分の研究やったほうがコスパは良さそうなのでほどほどに
- 前処理も勉強が必要
- いろいろなモデルを試す
- モデルだけじゃなく、手法(ランダムフォレストとか)も変えてみる
適度に沼にはまれればな、と思いました。 NLPのチュートリアルをするのでkaggleのkernelでやろうかな、とか思ってます。 たとえばSentiment Analysis on Movie Reviewsとか、 適度に業務とも関係がありそうで楽しそうだと思いました。 (しかもNLPのチュートリアルのネタになる)