Rで構文解析(CYK法)を実装する
RのAdvent Calendarに空きがある! やった! と喜び勇んで登録しました。 来てくださってありがとうございます。 これはR Advent Calendar2018、 14日目の記事です。
このエントリーには
「小さいサイズの規則の集合を使って解析アルゴリズムを実装」
という話をまとめました。
百聞は一見にしかず、ということで
CYK(Cocke–Younger–Kasami)法の
概要から入っていきたいと思います。
ちなみにCYKとCKYがごっちゃになってみんな諦めてる感があります。
規則の集合
CYK法は単語から構造を割り出す ボトムアップ型の文法解析です。 したがってまず、 「以下の単語列にはどんな構造を与えられるでしょうか」 という質問から始めます。
ヒロシ が 病院 で もらった 薬 を 飲んだ
上の単語列は構造的に曖昧です。 というのも、 「太郎が薬を飲んだ場所は病院なのかな」とか 「そもそも薬を飲んだ人はヒロシなのかな」とかが分かりません。
例えば、 「ヒロシの友達であるタロウは風邪で寝込んでいて、 ヒロシに薬をとって来るようにお願いした。」という文脈があって 上の文を読むと、 「(タロウは) ヒロシ が 病院 で もらった 薬 を 飲んだ 」 という読みもできます。
しかしそういう構造の曖昧性の話をする前に、 まずは各単語がどのような品詞ラベルを持つかを知ると話が楽です。 そこで下の辞書規則をRで定義してみましょう。 1つ目の例である”NP -> 薬”という規則を見てみると、 「NP(名詞句)は「薬」になるよ」と言っています。
# 辞書(dictionary)規則
rule.d <- c("NP -> 薬", "NP -> 病院", "NP -> ヒロシ",
"VP -> 飲んだ", "VP -> もらった",
"P -> が", "P -> で", "P -> を")
最初に見た単語列 (“ヒロシ が 病院 で もらった 薬 を 飲んだ “) に上の辞書規則を適用すると 下に示したような品詞の列が得られます。 まずはこのような「単語列を品詞列に変換する関数」 を作るところから始めます。
# "NP" "P" "NP" "P" "VP" "NP" "P" "VP"
単語列から品詞列へ(語彙規則)
語彙規則を使ってしたいことは、 「ヒロシ」はNP(名詞句)で、 「が」はPP(後置詞句)で、 「薬」は…という 「単語から品詞へのマッピング」です。 ただ、一度に書くと大変なので中間のテーブルを作ります。
# さっきの語彙規則の確認
rule.d
# -> で右辺と左辺を分離
char2cfg <- function(s) unlist(strsplit(s, " -> "))
# 中間テーブルを作る前に、ベクトルを作る
vector.d <- sapply(rule.d, char2cfg)
vector.d
# NP -> 薬 NP -> 病院 NP -> ヒロシ VP -> 飲んだ VP -> もらった P -> が
# [1,] "NP" "NP" "NP" "VP" "VP" "P"
# [2,] "薬" "病院" "ヒロシ" "飲んだ" "もらった" "が"
# P -> で P -> を
# [1,] "P" "P"
# [2,] "で" "を"
# これをガチャガチャして見やすいテーブルを作る
vector2table <- function(l) {
dimnames(l) <- list(c("LHS","RHS"), NULL)
as.data.frame(t(l), stringsAsFactors=FALSE) }
table.d <- vector2table(vector.d)
table.d
# LHS RHS
# 1 NP 薬
# 2 NP 病院
# 3 NP ヒロシ
# 4 VP 飲んだ
# 5 VP もらった
# 6 P が
# 7 P で
# 8 P を
上のテーブルを見ると、
単語の品詞を得るためには「与えられた単語」をRHS列にもつ行の
LHS列を抽出すれば
良さそうですね。
例えば “薬” の品詞を知りたい場合を考えましょう。
するとtable.dのRHS列で “薬” を持つ行は1行目にあるので、
1行目のLHS列の “NP”を引っ張ってくる、という形になります。
この操作を関数にします。
今後の拡張性のために、
まずはテーブルを与えて以下の関数を返す関数
をrhs2lhsとして作ります。
すでに与えられたテーブルを参照し、受け取った単語の品詞を返す関数
rhs2lhs <- function(table) function(rhs){
subset(table, table$RHS==rhs)$LHS}
# テーブルをもらって「単語をもらって品詞を返す関数」を返す関数
rhs2lhs(table.d)("ヒロシ")
# [1] "NP"
ちゃんとtable.dを与えてから “ヒロシ”という文字列を与えると
“NP”という品詞が返ってきています。
上で動作を確認できたので最後の準備です。
解析したい文がスペース区切りで与えられるとして、
そのスペース区切りの単語列をChar型のベクトルにします。
input <- "ヒロシ が 病院 で もらった 薬 を 飲んだ"
char2vector <- function(s) unlist(strsplit(s, "[ ]"))
vector.input <- char2vector(input)
vector.input
# ヒロシ が 病院 で もらった 薬 を 飲んだ
そしてそのベクトルに上の関数をsapplyすればよいのです。
すると単語列を品詞列にマップできます。
sapply(vector.input, rhs2lhs(table.d))
# ヒロシ が 病院 で もらった 薬 を 飲んだ
# "NP" "P" "NP" "P" "VP" "NP" "P" "VP"
品詞の対から句構造へ(句構造規則)
次は品詞の対を句構造に組み込む関数を考えます。 といっても、先ほどの語彙規則と手順は全く同じです。 句構造と句構造のテーブル、 そして句構造のペアからLHSを求める関数は 以下のように定義できます。
# 句構造(phrase)規則
rule.p <- c("S -> PP VP" ,
"PP -> NP P",
"NP -> VP NP",
"VP -> PP VP")
# テーブル
table.p <- vector2table(sapply(rule.p, char2cfg))
# 関数
rhs2lhs(table.p)("PP VP")
# [1] "S" "VP"
# ちゃんと動く
試しに “PP VP”の品詞の対をスペース区切りで与えると、 しっかりと “S”と “VP”を返していますね。
句構造でパースする
さて、上で作成した句構造規則を回します! 今回扱うCYKは上の品詞の列を行列の対角に与えてあげます。 行列と言いつつ、配列を作っているのがミソです。 作る意味を伝えないとこの配列を作る嬉しさも伝わりませんが、 とりあえず行列を作ってみましょう。
三角行列を作る
まずはNAの配列を作り、
# まずは入力の文字列の大きさをnとする
n <- length(vector.input)
# [1] 8
# 8x8x1の配列を作る
triangle <- array(dim = c(n, n, 1))
triangle
# , , 1
#
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
# [1,] NA NA NA NA NA NA NA NA
# [2,] NA NA NA NA NA NA NA NA
# [3,] NA NA NA NA NA NA NA NA
# [4,] NA NA NA NA NA NA NA NA
# [5,] NA NA NA NA NA NA NA NA
# [6,] NA NA NA NA NA NA NA NA
# [7,] NA NA NA NA NA NA NA NA
# [8,] NA NA NA NA NA NA NA NA
単語列を品詞(pos)のベクトルに変換したものを
先ほどの配列の対角においてあげます。
(余談なのですが、
<<-を使ってグローバル変数を返すのが嫌なので、
もし改善方法をご存じの方がいらっしゃれば
ヘルプしたいです。)
pos <- sapply(vector.input, rhs2lhs(table.d))
pos
# ヒロシ が 病院 で もらった 薬 を 飲んだ
# "NP" "P" "NP" "P" "VP" "NP" "P" "VP"
mapply((function(x,i) triangle[i,i,1] <<- x),
pos, 1:(length(pos)))
# global変数への挿入をするため仕方なく、 <<- を使っている。
triangle
# , , 1
#
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
# [1,] "NP" NA NA NA NA NA NA NA
# [2,] NA "P" NA NA NA NA NA NA
# [3,] NA NA "NP" NA NA NA NA NA
# [4,] NA NA NA "P" NA NA NA NA
# [5,] NA NA NA NA "VP" NA NA NA
# [6,] NA NA NA NA NA "NP" NA NA
# [7,] NA NA NA NA NA NA "P" NA
# [8,] NA NA NA NA NA NA NA "VP"
ここまでの話からなんとなく察していただけたかもしれませんが、 最終的な目標は右上の[1,8]のノードまで解析を進めることです。 いかにも先ほど作った「NPとPがくっつくとPPになる」 というような関数を適用できそうです。 しかし適用する順番にはひと工夫必要です。
句構造規則を適用する順番
適用する順番を考える段階になって、 冒頭のgifが活きてきます。
少し観察してみましょう。
LHSが右上まで動くのを3回ほど見るとパターンがわかるかもしれません。
LHSは左上から右下へ、という動きを、
右上まで繰り返していますね。
したがって、対角より右上の部分はまんべんなく調べられます。
いかにもforで回してます。
しかも左上から右下へ、というforの上に、
その動きを一段ずつ右にずらしていく
forもあることが分かると思います。
LとRの動きはどうでしょうか。
一見バラバラにも見えますが、
Lは右に動き(つまり列のカウントが増し)、
Rは下に進んでいます(つまり行のカウントが増加している)。
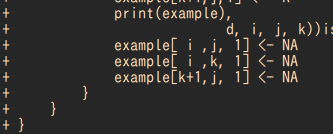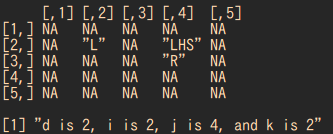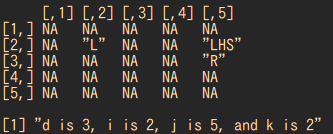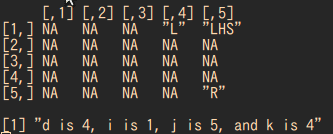
つまり、$a_{i,j}$にあるLHSは
カウンターを$k$とした時、
$a_{i,k}$と$a_{k+1,j}$から求めています。
そして$k$が増えるごとに
Lは右に、Rは下に進みます。これが最後のforです。
この3重のforは以下のように書いています。
なお、簡単にするためにnは5にしています。
n <- 5
example <- array(dim = c(n, n, 1))
for(d in 1:(n-1)){
for (i in 1:(n-d)){
j <- i + d
for (k in i:(j-1)){
Sys.sleep(1)
example[ i ,j,1] <- "LHS"
example[ i ,k,1] <- "L"
example[k+1,j,1] <- "R"
print(example)
print(sprintf("d is %d, i is %d, j is %d, and k is %d",
d, i, j, k))
example[ i ,j, 1] <- NA
example[ i ,k, 1] <- NA
example[k+1,j, 1] <- NA
}
}
}
これで句構造規則を適用する順番は実装できました。
つまり、上のデモにおいて
“LHS” と “L”, “R”の3つが出ている時点で
“LHS -> L R” という規則があるかを調べます。
その時には先程作ったrhs2lhs(table.p)を使えます。
その結果がベクトルで返ってくるので、
先ほど作った配列triangleに工夫して入れて更新すれば、
あとは右上まで構造がつくれます。
必要なライブラリーの導入
外部パッケージにはrbind
を配列にも拡張したabindを利用します。
install.packages("abind")
library(abind)
CYK
三重のforの中では配列を利用したクールなことをしています。
微妙に長くなるので説明はしませんが、
特定の座標のLとRをベクトルとして取得し、
そのベクトルの組み合わせをouter関数でとり、
rhs2lhs(table.p)をsapplyしてます。
その結果もまたベクトルなので、
その要素数分の行列を作って配列の新しい要素としてabindしています。
# triangleの準備
n <- length(vector.input)
triangle <- array(dim = c(n, n, 1))
mapply((function(x,i) triangle[i,i,1] <<- x),
pos, 1:(length(pos)))
triangle
# CYKの実行
for(d in 1:(n-1)){
for (i in 1:(n-d)){
j <- i + d
for (k in i:(j-1)){
ik <- triangle[ i , k, ]
k1.j <- triangle[k+1, j, ]
product <- c(outer(ik, k1.j, FUN=paste))
m <- unlist(sapply(product, rhs2lhs(table.p)))
if(length(m)==1){
triangle[i,j,1] <- m
}else if(length(m)>1){
len.m <- length(m)
tmp <- array(dim = c(n, n, len.m))
tmp[i,j,1:len.m] <- m
triangle <- abind(triangle,tmp)
}
}
}
}
その結果は大量の行列のペアになります。 それを座標ごとに引っ張ってきて行列に文字列として 組み込めば完成です。
# 最後の出力は配列の奥行きの要素を文字列として結合するのみである。
cat.table <- array(dim = c(n, n))
for(i in 1:n){
for(j in 1:n){
cat.table[i,j]<- toString(na.omit(triangle[i,j,]))
}
}
cat.table
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
# [1,] "NP" "PP" "" "" "S, VP" "NP" "PP" "S, VP, S, VP, S, VP"
# [2,] "" "P" "" "" "" "" "" ""
# [3,] "" "" "NP" "PP" "S, VP" "NP" "PP" "S, VP, S, VP"
# [4,] "" "" "" "P" "" "" "" ""
# [5,] "" "" "" "" "VP" "NP" "PP" "S, VP"
# [6,] "" "" "" "" "" "NP" "PP" "S, VP"
# [7,] "" "" "" "" "" "" "P" ""
# [8,] "" "" "" "" "" "" "" "VP"
最後に
今回はCYK法を実装してみたのですが、 分かりづらかったでしょうか、 それとも分かりやすかったでしょうか。 自分のブログをこういう場に出すのは初めてなので緊張してます。
人って文をどういうふうに理解してるのかなぁ、 という疑問を考えていたらアルゴリズムに手を出していました。 こういうふうに解析のアルゴリズムを理解できただけでも 「プログラミングを勉強しててよかったなぁ」って思いました。
今後はEarley法や左隅型の構文解析、確率文脈自由文法、 識別モデルによる順位再付与、 遷移型モデルによる句構造解析あたりも攻めて見ます。
それではみなさま、良いお年をお迎えください!
参考になったリンクなど
- Chart Parsing: The CYK Algorithm
- Grammar (needs to be in CNF)
- The CYK Algorithm
- Dor Altshuler: CKY (Cocke-Kasami-Younger) and Earley Parsing Algorithms
- CKY Parser for Japanese
- JAIST: 自然言語処理論I
- PCFG構文解析法
- 【python】CKY法をpythonで実装